
技術営業でお客さまの悩みをよく聞く立場である、私は日々お客さまの悩みを解決できる方法に貪欲です。その実現方法はさまざま。これを概念実証(PoC:Proof of Concept)って言います。
さて、今回はオブジェクトストレージを使います。
GMOクラウドアカデミーでも紹介記事の多いオブジェクトストレージの利用方法を軸に比較してみましょう。GMOクラウドアカデミーやテクニカルガイドでも取り上げられるものの、まだまだ普及していない感が否めません。物理HDDと異なり、使用量・期間・転送量が影響するため、企業用途では価格メリットは感じても、実際に利用してみないと月額や年額コストは見えにくいため採用される企業さまはまだ少ないです。ただオブジェクトストレージの料金は容量だけではない点は注意が必要です。
オブジェクトストレージを利用するには一手間掛けてやる必要があり、プログラムを作成しその中でライブラリを経由して使ったり、オブジェクトストレージを扱えるパッケージソフトを利用することになります。そのため日々サーバーを運用するエンジニアであれば大丈夫でも、webデザイナーや兼任情シスさんなどサーバーとあまり縁が無い立場の方は、ちょっと縁遠く感じてしまうかも知れません。そんなあなたの力になれば。
いくつか黒画面を使いますが、失敗したら仮想サーバーを作り直せば大丈夫!
今回は「s3cmd」というもともとはam○zon s3というオブジェクトストレージの先駆け向けに開発されたパッケージですが、s3互換のオブジェクトストレージであれば使用可能です。ALTUSのオブジェクトストレージもs3互換のAPIを搭載しているので、おおかた利用可能です。
・CentOS7仮想サーバー(6では無理でした)
(今回はALTUS。スナップショットをコマめにとれば再作成が早いですよ!)
→スナップショットから仮想サーバーを作成はコチラ
GMOクラウドサポートサイト - ALTUS Basicシリーズ ディスクスナップショットの作成
・s3cmd (CentOSの拡張版(EPEL)にある最新版) 2015年12月現在 version1.6.0
※追記:2016年6月に1.6.1がリリースされました
進め方としては、こんな感じです。
Ⅰ.CentOS7を作成し、準備する
仮想サーバーのスペックは用途に応じてですが、s3cmdのテストであればミニサーバーでも可。今回検証時には、他の用途もあって「2 vCPU / 4 GB Memory」作ってみました。
ISOイメージからの仮想マシン作成はすいません、割愛しちゃいます。
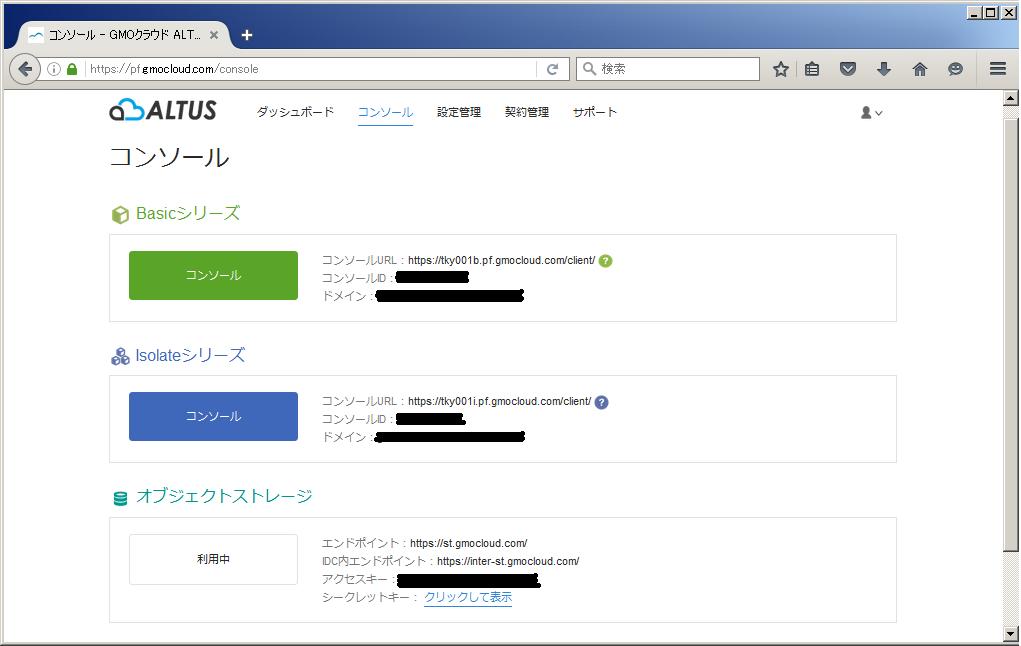
あとオブジェクトストレージは、利用時は[Access Key]と[Secret Key]と呼ばれる利用ユーザーしか知らない情報と、エンドポイントと呼ばれるURLを知っておく必要があります。これはどのベンダーのオブジェクトストレージでも存在しますが、呼び名がちょっと違う場合もあるのでご注意ください。
ALTUSの場合は、ALTUSポータルの「コンソール」タブから確認できます。
[Access Key] = [アクセスキー]
[Secret Key] = [シークレットキー](クリックして表示)
[エンドポイント](https://st.gmocloud.com/)は機能を使うためのAPI用URLのことです。オンプレミスな環境や弊社別サービス(専用サーバー、Private cloudなど)からはインターネットを経由する必要があるため、普通はこっちを使います。
[iDC内エンドポイント](https://inter-st.gmocloud.com/)も条件によっては利用可能です。通信料がかからない反面、ALTUS内からしか利用できない、性能控えめなど、上記エンドポイントに条件が付いてます。今回のようなPoC利用やアーキテクチャを知り尽くした人には向いてます。
Ⅱ.パッケージを最新に更新
すいません。ここから早速、黒画面です。
作成したサーバーにコンソールやターミナルソフトで接続し、管理者権限(root権限)付きユーザーでログインをして、まずは最新のパッケージに更新をしておきます。
◆最新へ更新
もし、[y/N]のような画面で止まってもy(Yes)を入力して進みましょう。
ALTUS であれば、最新に更新が終わったタイミングでルートディスクのスナップショットを作成しておくと、あとで失敗してもゲームのセーブポイントのように戻れるので楽なのでおススメです。
Ⅲ.EPELをインストール
次はEPEL(エンタープライズ Linux 用の拡張パッケージ)をインストールします。EPELは実際に何かをするパッケージと言うよりかは、さまざまな拡張用パッケージをインストールできるようにするパッケージです(ややこしくて、すいません)。
◆EPELのインストール
◆最新へ更新(EPELも含めて最新へ)
Ⅳ.s3cmdをインストール
EPELを使えるようにしたので、EPELの中から拡張パッケージがインストールできるようになっているはずです。
◆s3cmdをインストール
もしここでインストール時にエラー(s3cmd が見付からないなど)の場合は、EPELのインストールが正しくできているか確認してみてください。
Ⅴ.s3cmdを使ってみませう
無事にs3cmdがインストールできたならば、初期設定を行います。利用ユーザーごとに行う必要があります。例はrootユーザーですが、その他コマンドを利用するユーザーは設定する必要があります。随所にA○azon S3と出ますが、細かいことは気にしません。
# s3cmd --configure
◆アクセスキーを入力
Access Key []:
◆シークレットキーを入力
Secret Key []:
◆A○azon 用設定(不要のためデフォルト設定のままエンターキーで継続)
Default Region [US]:
Encryption password:
Path to GPG program [/bin/gpg]:
Use HTTPS protocol [Yes]:
HTTP Proxy server name:
◆アクセスのテストするかを聞かれますが、[n]を選択
Test access with supplied credentials? [Y/n]
◆保存するかを聞かれますので、[y]を選択
Save settings? [y/N]
これでユーザーのホームディレクトリに.s3cfgという設定ファイルが作成されます。
ただこれではまだ弊社オブジェクトストレージには使えないため、設定ファイルを編集します。
◆設定ファイルの編集
下記の項目をviエディタなどで書き換えます。
ファイルは隠しファイルのため、名前の先頭に.(ドット)があるので気をつけてください。普通にlsコマンドなどで探すと見付からず、ls -a などのオプションが必要です。またlinuxの黒画面でエディタを使いたくない人は、sftpなどでwindowsPCまで.s3cfgファイルを持っていき、メモ帳で編集してください。
host_base = s3.amazonaws.com
host_bucket = %(bucket)s.s3.amazonaws.com
signature_v2 = False
host_base = st.gmocloud.com
host_bucket = %(bucket)s.st.gmocloud.com
signature_v2 = True
◆s3cmdのテスト
初期設定ができたかテストしてみましょう
下記のようなエラーが表示されず、コマンドが終了すれば大丈夫です。
まだバケットも作成していなければ、このコマンド結果は何も出なくてOKです。
「エラー1」
ERROR: Configuration file not available.
ERROR: Consider using --configure parameter to create one.
・アクセスキーが入っていない
「エラー2」
「エラー3」
◆s3cmdを使って、バケット(データの入れ物)を作成する
さあ、いよいよ利用開始です。ここから課金が発生しますよー
Bucket 's3://apple/' created
と表示されると[apple]バケットの作成完了です。
◆作成できたか表示してみる
2016-06-28 15:28 s3://apple
このように、作成日付とバケット名が見えると作成できてます。
ちなみにバケットを作成すると¥1です。
◆その他操作
# man s3cmd
・バケット作成
# s3cmd mb s3://バケット名
・バケット削除(バケット内が空でなければ削除されない)
# s3cmd rb s3://バケット名
・オブジェクト保存(ファイルの保存)
# s3cmd put ファイル名(local) s3://バケット名/ファイル名
・オブジェクト取り出し(ファイル取り出し)
# s3cmd get s3://バケット名/ファイル名 ファイル名(local)
・ディレクトリ作成(空ディレクトリが作成できないため、ファイルと一緒に作成)
# s3cmd put -r ディレクトリ名/適当なファイル s3://バケット名/
・容量計算
# s3cmd du
・コマンド設定
# s3cmd --configure
・helpコマンド
# s3cmd -h
Ⅵ.使って気付いたこと
s3cmdを使ってまずは、データを保存したり取り出したりできるようになりました。
使う際に、どうも気になったことを記載します。
・空ディレクトリが作成できない
⇒以外と普段から空のディレクトリを作成している自分に気付きました。コツは何でもいいのでファイルと一緒にputすると大丈夫
・ローカルよりは流石に遅い
⇒当たり前なんですが、通信越しにファイルを保存することを意識する。コピー1つが遅いのと、通信が切れると保存が失敗する。
※ftpやscpと同じ考えですね。
・大きなファイルが早い?
⇒気のせいかと思い、中の人間に聞きました。(職業柄役得)
これは弊社オブジェクトストレージ仕様で、大容量ファイルやアーカイブ用途のためにチューニングされてるためでした。「s3cmd」だから、「オブジェクトストレージ」だから、というのはなさそうです。他社さんのオブジェクトストレージはどうなんでしょうか...
・正直、コマンドだらけで使いづらい
⇒私は大丈夫ですが、方々から聞きました。きっと便利なはずだが、このままだと運用できない。
コスト面を考えても、普及の足かせにも見えました。
これは次項で何とかしましょう!
Ⅶ.さらに活用!
弊社のオブジェクトストレージが大容量・アーカイブ向けと分かったので、それに併せて利用方法を考えてみたいと思います。
普通に考えて、アーカイブ向けなので1日1回、や週1回にログやデータベースのダンプを保存するのが良さそうですね。ftpやscpでアーカイブするにせよ、通信は切れることを想定して行います。
ただ、どうやっていいかどうかは。。。難しいのでまずは本家本元を見てみましょう。
◆yum コマンドでパッケージ元を探す
この結果として表示されたURLを見てみましょう。
s3cmdの中には、sync機能を解説してくれています。
S3cmd S3 Sync How-To(外部サイト)
これはいわゆるLinux系の非同期でのデータをやりとりしたり、アーカイブとして使われるrsync/lsyncといった機能と似ているようです。これを使ってみましょう。
動機させるテスト環境としては、よくありがちな1日1回のバックアップを取得してみましょう。
バックアップするのは、細切れなデータと大きな塊データの2種類。
save/target1 というディレクトリの下に1個100KB程度のdata1.csv,data2.csv … data10.csv
save/target2 というディレクトリの下に1個400MB程度のdump.img
これをmondayというバケット直下に保存していきます。
無駄な転送もしたくないため、条件付きの転送(Conditional transfer)をやってみたいと思います。
◆バックアップ
--skip-existing 新しいものだけ転送する
--limit-rate= 秒間で転送するバイト数を指定(kでKB、mでMB)
--stop-on-error コピーのエラーで停止する
これでできました。
ただし、s3cmdが名前が異なっても同じデータを見分けるため
remote copy: 'target1/data1.csv' -> 'target1/data2.csv'
remote copy: 'target1/data1.csv' -> 'target1/data3.csv'
のように、同一ファイルのコピー元は1カ所となる仕様のようです。
テスト環境のファイル作成をサボったのがs3cmdにばれてビックリしました。
あとはこれをlinuxのcronに登録しておけば、1日1回のバックアップが可能です。
使ってみた感想としては、小さなファイルを転送するのに掛かる時間より、サイズの大きいファイルを転送する時が体感的に早く感じました。(条件によっても変わるのでご注意ください)
通信経由でのバックアップのため、通信切れやタイムアウトによる運用はもう少し考えていく必要はありますが、それでもコストメリットを考えてもオブジェクトストレージを検討してみるのはいいかも。





{kind=link}